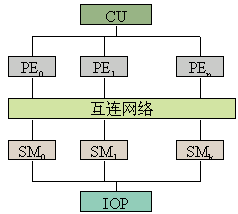
共享存储器结构的SIMD计算机如图10.4所示。这是一种集中设置存储器的方案。共享的多体并行存储器SM通过对准网络与各处理单元PE相连。存储模块的数目等于或略大于处理单元的数目。同时在存储模块之间合理分配数据,通过灵活、高速的对准网络,使存储器与处理单元之间的数据传送在大多数向量运算中都能以存储器的最高频率进行,而最少受存储冲突的影响。
这种共享存储器模型在处理单元数目不太大的情况下是很理想的。Burroughs Scientific Processor (BSP)采用了这种结构。16个PE通过一个16×17的对准网络访问17个共享存储器模块。存储器模块数与PE数互质可以实现无冲突并行地访问存储器。
无论采用哪种存储方案,互连网络的存在都是必要的。在共享内存方案中,它是内存与处理单元之间的必由之路。在分布内存方案中,即使处理单元所需数据在大多数情况下能由本地存储器提供,处理单元之间的数据交往仍是必不可少的。在图10.3中,各处理单元PE之间可以经过两条途径相互联系:一条是直接通过数据寻径网络;另一条是数据从LM读至阵列控制部件,然后通过公共数据总线"广播"到全部PE中。在处理单元数目很多的并行处理机中,PE之间的直接数据通路只能是很有限的,这决定了系统的固定结构和专用处理机的性质。这种局限性需要从互连网络的研究中得到解决。
SIMD计算机执行向量指令,对向量的分量进行算术、逻辑、数据寻径和屏蔽操作。在位片SIMD计算机中的向量是二进制向量。在字并行SIMD计算机中向量的分量是4字节或8字节的数。
所有SIMD指令都必须使用长度为n的向量操作数,其中n是PE的个数。SIMD指令与流水线向量处理机的指令类似,不同之处是多PE的空间并行性代替了流水线的时间并行性。
数据寻径指令包括置换、广播、选播以及多种循环和移数操作。在任何指令周期,通过屏蔽操作可以允许或禁止某些PE参加运算。
上述SIMD结构的所有I/O动作都是由主机处理的。在主机和阵列控制部件之间有一个专用的控制存储器,它是一个存放程序和数据的中间存储器。在启动程序之前,把划分好的数据集合分布到本地存储器或共享存储器模块。主机管理大容量存储器或计算结果的图形显示。在控制部件的协调下,标量处理机与PE阵列并发地运算。共享存储器并行处理机
共享存储器模型的处理单元数目一般不多,几个至几十个。