由于矩阵乘是二维数组运算,故它比矩阵加要复杂一些。设A、B和C为三个8×8的二维矩阵。若给定A和B,则C=A*B的64个分量可利用下列公式计算。
如果在SIMD计算机上求解这个问题,则可执行下列FORTRAN程序
DO 10 I=0,7
C(I, J)=0
DO 20 K=0, 7
20 C(I, J)=C (I, J )+A(I, K)*B(K,J)
10 CONTINUE
类似的程序在SISD计算机上要用K,I,J三重循环才能完成,每重循环执行8次,共需512次加乘时间(不考虑其它循环控制指令所需时间)。而在SIMD计算机上执行上面的程序时,如果利用8个处理部件并行计算,则J循环只需一次即可完成,I、K循环照旧。这样,便可使速度提高到8倍,即缩短为64次加乘时间。局部存储器中的数据分布如下:
|
在并行处理机上,J循环只需一次。速度提高到8倍。
PE0:c00=a00b00+a01b10+a02b20……+a07b70
PE1:c01=a00b01+a01b11+a02b21……+a07b71
……
PE7:c07=a00b07+a01b17+a02b27……+a07b77
PE0:c10=a10b00+a11b10+a12b20……+a17b70
PE1:c11=a10b01+a11b11+a12b21……+a17b71
……
PE7:c17=a10b07+a11b17+a12b27……+a17b77
……
PE0:c70=a70b00+a71b10+a72b20……+a77b70
PE1:c71=a70b01+a71b11+a72b21……+a77b71
……
PE7:c77=a70b07+a71b17+a72b27……+a77b77
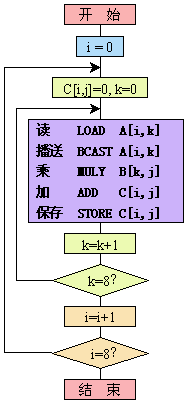
从表面上看,这个程序在每个处理部件内部的执行过程和传统的SISD计算机是一样的,但是由于8个处理部件执行同一指令流,并行操作,故实际解决问题的方式是不同的:第一,控制器执行的指令,表面上是标量指令,但实际上等效于向量指令(如向量取、向量存、向量加、向量乘等)。第二,执行这个程序对于A、B、C向量在处理单元存储器中的分布方案提出了一定的要求。作乘法时,操作数B(K,J)都从本处理部件的PEM中读取;但被乘数A(I,K)对所有处理部件0£J£7都是一样的,它一般都不在本处理部件存储器内。因此,要利用阵列处理机的"广播"功能,把一次循环的公共系数A(I, K)取出后送到控制器,再广播到全部8个处理单元的RGA中去。