MWSIS: Multimodal Weakly Supervised Instance Segmentation with 2D Box Annotations for Autonomous Driving.
Accepted by AAAI-2024
Guangfeng Jiang, Jun Liu*, Yuzhi Wu, Wenlong Liao, Tao He, Pai Peng*
[code]
[paper]
[website]
Abstract
Instance segmentation is a fundamental research in computer vision, especially in autonomous driving. However, manual mask annotation for
instance segmentation is quite time-consuming and costly. To address this problem, we propose a novel framework called Multimodal Weakly Supervised
Instance Segmentation (MWSIS), which incorporates various fine-grained label generation and correction modules for both 2D and 3D modalities to
improve the quality of pseudo labels, along with a new multimodal cross-supervision approach.
Visualization
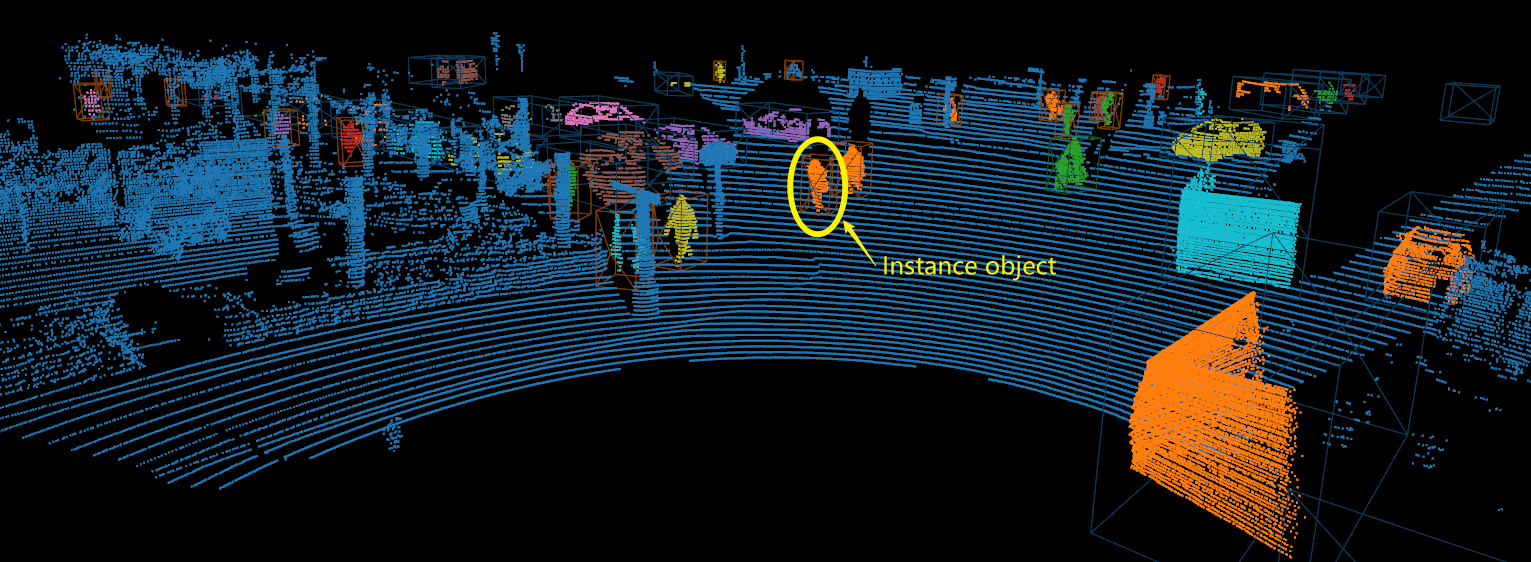
Figure: The above figure shows the result of 3D instance segmentation in the LiDAR point cloud scence.
Blue points represent background points, other colored points represent foreground points, and different colors represent different instances. For example, the yellow ellipse circled
in the figure above is a human instance object.
Spatial and Temporal Awareness Network for Semantic Segmentation on Automotive Radar Point Cloud.
Accepted by IEEE Transactions on Intelligent Vehicles
Ziwei Zhang, Jun Liu*, Guangfeng Jiang
Abstract
Radar sensors are vital for autonomous driving due to their consistent and dependable performance,
even in challenging weather conditions. Semantic segmentation of moving objects in sparse radar
point clouds is an emerging task that contributes to improving the safety of autonomous driving.
In this paper, we propose a scheme to process points of multi-scan data into a single frame with
the availability of temporal features. Our novel network, called Spatial and Temporal Awareness
Network (STA-Net), enables points at different times to interact and establish their spatiotemporal
connections to comprehend the
surroundings of these points.
Visualization
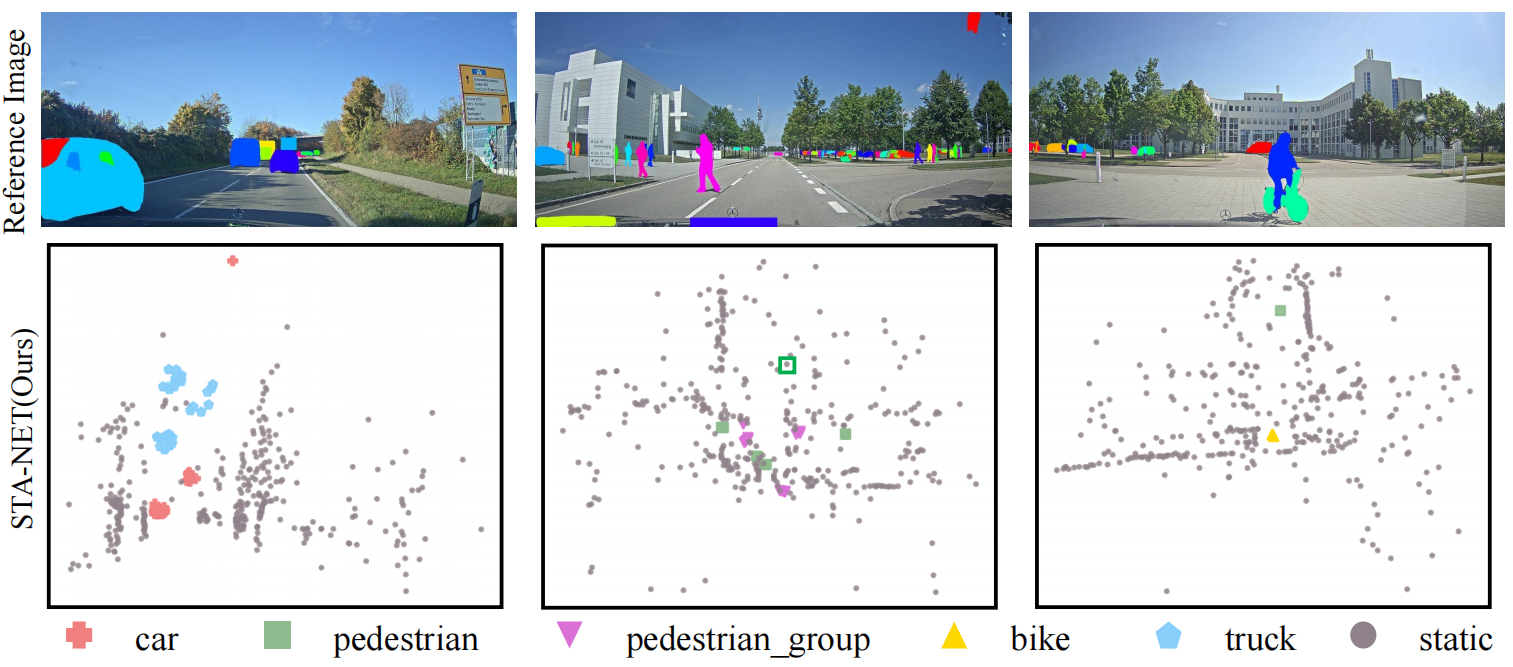
Figure: Visualization of semantic segmentation results on the RadarScenes dataset. Each point is represented by a symbol, and the type of symbol represents
the class of the point. The red rectangles indicate the background points that are misclassified as moving objects, while the green rectangles indicate that the
types of the objects are incorrectly predicted.