Lab 4: Garbage Collector
Lab Overview
In this lab, your job is to design and implement a garbage collector called Gimple (Garbage Collector is Simple) and link it into your Tiger compiler, so that it can manage the Java heap in an automatic way. The Gimple garbage collector is a simple copying collector based on the Cheney algorithm. The code generator you will be using is the C code generator from part A of the the previous lab. However, most parts of the Gimple garbage collector is independent of the specific code generator, which means that it's of no difficulty to port and link Gimple garbage collector to other code generators.There are two parts in this lab. In the first part, you'll design and implement various GC maps, and modify your current C code generator to generate them. GC maps are compiler-generated data structures to tell Gimple various information it needs to collect garbage; for instance, the GC maps will tell Gimple the locations in memory of declared variables (of reference types) in a given method, so that Gimple can start, from these locations, to traverse the Java heap for reachable objects; and also GC maps will tell the Gimple collector the detailed memory layout of of heap-allocated objects, so that Gimple can traverse each object's children (i.e., fields with reference types).
And in the second part of this lab, you'll design and implement the Gimple garbage collector based on Cheney's copying algorithm.
Getting Started
First, check out the source for Lab4:$ git commit -am 'my solution to lab3' $ git checkout -b Lab4 origin/Lab4these commands will commit your changes to Lab3 branch to your local Git repository and then create and check out the remote Lab4 branch into your local Lab4 branch.
Again, you will now need to merge your code from Lab3 into the new Lab4 branch:
$ git merge Lab3Don't forget to resolve any conflicts before commit to the local Lab4 branch:
$ git commit -am 'lab4 init'
Now, you can import the new Lab4 code into your Eclipse. There is no new files for this lab. You will complete this lab by modifying existing code.
Hand-in Procedure
When you finished your lab, zip you code and submit to the school's information system.Part A: GC Maps
In this lab, you will only need to consider garbage collection problems on uniprocessors, for it's much simpler than a collector on concurrent or realtime systems. During the execution of a Java application on a uniprocessor, the application allocates objects in the Java heap, and whenever the application need to allocate more objects but there is no enough space left in the Java heap, the application will be temporarily stopped (the so-called stop-the-world) and the garbage collector takes over to reclaim garbages in the Java heap. And after this round of collection, hopefully there is enough space available so that the application can resume.
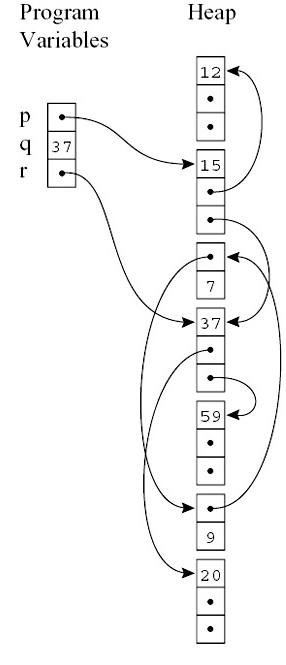 From the conceptual point of view, during the
execution of a Java application, all heap-allocated objects
form a directed graph in the heap, with objects as graph
vertex and fields of reference types as graph edges. For
instance, consider
the sample Java heap at the right hand, the program variable
From the conceptual point of view, during the
execution of a Java application, all heap-allocated objects
form a directed graph in the heap, with objects as graph
vertex and fields of reference types as graph edges. For
instance, consider
the sample Java heap at the right hand, the program variable
p points to an object with value 15
in the first field, and this object is a graph vertex with
two fields (of reference types) followed by the field 15.
Conceptually, the task of a garbage collector can be divided into two sub-tasks: scanning and collecting. During the scanning phase, the collector scans through the (object) directed graph to mark which objects are reachable whereas which are not. Then, during the collecting phase, the collector will reclaim unreachable objects to obtain more spaces. After the collection, it's often the case that there will be more spaces in the heap for future allocations. Of course, the division of the garbage collection into canning and collecting is more of explanation purpose. Many real garbage collectors combine the two phases in some way or even make use of other strategies.
So, for the graph traversal to work, two challenges must be
addressed: first, how does
the garbage collector know where to start to traverse the
directed graph? i.e., the garbage collector must have
enough knowledge about the positions of graph's roots.
For instance, consider the right-hand graph, the garbage
collector must find out the positions for declared
program variable
p and r.
Second, during the
scanning phase, when
the garbage collector walks to a graph vertex (an Java object), how
does the collector know how
many fields the current vertex has and which of these fields are
references, thus should be further traversed
(i.e., the node's out-degrees, in the graph theory terminology)? For
instance, consider the right graph, when the collector walks to
the graph vertex with value 15 from the
declared variable p, it must have the knowledge that
this object contains two reference fields at offset 1 and 2 separately,
so that the graph traversal can continue with these two fields.
To address the first challenge, the garbage collector need the information of the positions of declared reference variables in a machine, the positions can be any region of a machine: global data area, stack slots, machine registers, etc.. The data structures to encode this information are often called the memory GC maps. And it's the compiler's task to generate such data structures.
To address the second challenge, the garbage collector need the information of number of fields contained in an object and among those which are references. The data structure to encode this information is often called the class GC maps. And also it's the compiler's task to generate such data structures.
Naming Allocations
Now, you'll write some code. The first task you will finish is to modify your current C code generator from the previous lab. There are some subtle issues arising when the code generators is attached a garbage collector. One such issue is the nameless allocations, which means that the the allocated object is not assigned to a declared variable immediately after its allocation. Consider this code:
1: class A{
2: void foo(){ new B().bar(); }
3: }
4: class B{
5: void bar(){ new B(); }
6: }
Both of the object allocations at line 2 and 5 are nameless
allocations.
The problem with the above code is that if the garbage
collection takes place after the allocation at line 2 but
before the allocation at line 5, then the garbage collector
will have no way of finding out where the allocated
object at line 2 is located in the heap. As a result, the collector
will reclaim the space occupied by that object and
thus this application may crash.
Exercise 1.
Explain in more detailed why this program may crash or go
wrong if the garbage collector reclaims the object allocated
at line 2. You may add some code to the method bar
to support your conclusion.
There is a simple solution to this problem: you can
just name the object just after its allocation. Thus, each
allocation expression new id () can be
translated into a C comma expression (x=new id(), x)
where x is a freshly generated
variable. Of course, a new local variable declaration
id x; should be generated. With this naming
process, the above code will be roughly translated to:
1: class A{
2: void foo(){ B x; (x=new B(), x).bar(); }
3: }
4: class B{
5: void bar(){ B y; (y=new B(), y); }
6: }
Exercise 2.
Explain briefly why there is NO problem for the garbage
collector with the new code. Should you initialize declared
variables x or y with null, why
or why not?
Exercise 3.
Modify the visitor (codegen.C.TranslateVisitor.java)
to assign a unique
name to every allocation (object or array) as discussed above. Note
that you maybe don't need to write a special class to represent
the comma expression.
Memory GC Maps
Now you'll design and implement the memory GC maps data structures. The concrete data structures of the memory GC maps are highly dependent on the language being compiled. In the MiniJava language, there is no global (static) variables, so you don't need to generate information for them. And the only possible references remained are method arguments and locals, so the compiler can mark which arguments and locals are references and the exact locations of them. Typically, all such kinds of references are located on the C call-stack, so you can call them stack GC maps.The data structure you'll use to encode the stack GC map is the bit-vector, which is just a string of "0" and "1"s, with "0" for non-reference variables and "1" for references.
Exercise 4.
Modify your current code generation part for methods (file
codegen.C.PrettyPrintVisitor.java), to generate and
print
out two memory GC maps (in bit-vector data structure) for
each method: one GC map for method arguments and another
one for method locals.
For instance, consider this method:
T f (D this, int arg1, A arg2, B arg3){
A local1;
int local2;
C local3;
... // statements
}
you should generate two memory GC maps just before
the code generated for the method f, roughly like
these (the name of the bit-vectors are of your choice):
char *f_arguments_gc_map = "1011"; char *f_locals_gc_map = "101";
Call Stack and GC Stack
Besides the memory GC maps for a method, the Gimple garbage collector should also have the knowledge of where to locate the arguments and locals (i.e., starting address). As you are using the C code generator, so it's important to recall here the standard C calling convention and the typical layout of the C call stack you are using. One important fact to note is that the calling convention and call stack layout is highly architecture dependent, here and afterwards, we'll suppose that you're using the x86 ISA, if you're compiling to a different architecture other than x86, it will be different (but similar techniques can be applied as well).
The C calling convention and call stack layout can be
well explained by the function f from the
above exercise. The following figure illustrates the
stack layout of f on the x86 ISA:
----------------------------------------------------------> low address
| arg3 | arg2 | arg1 | this | ret | ebp | locals?
-----------------------------------------------------------
^
ebp
the
arguments arg3, arg2, arg1, this are located continuously
at relatively higher address of the call stack,
followed by a saved return address ret and
a saved ebp register. Thus, it's easy
to locate all arguments: the compiler can just tell
the Gimple garbage collector the address of the first argument
this, then Gimple can find out all arguments with
reference types with the memory GC map for arguments.
Exercise 5. Consider this method again:
T f (D this, int arg1, A arg2, B arg3){
A local1;
int local2;
C local3;
... // statements
}
Given the address of the first argument this and
the memory GC maps:
char *f_arguments_gc_map = "1011";how can you figure out all the address of the arguments with reference types?
Unfortunately, unlike arguments, you can say nothing about the layout of locals on the call stack. In fact, the C compiler is free to determine any layout for all the method locals: the compiler may rearrange the locals any order other than the order specified by the program text; or the compiler may not put all locals adjacently; or the C compiler may put some or all of the locals (via the so-called register allocation optimization) into machine registers instead of on the call stack, etc.. So, generally speaking, it's unreliable to suppose any specific stack layout for locals.
The solution you'll be using here is to introduce another
stack to hold the function locals, and you can call the new
stack the GC stack. Each stack frame in the GC stack
contains the
following elements: the memory GC map for argument;
the address of the first argument; the memory map for locals;
all the locals. For instance, consider again the method f
from the above exercise, you should generate, for the method
f, a data structure declaration for f's GC frame
of this form:
struct f_gc_frame{
void *prev; // dynamic chain, pointing to f's caller's GC frame
char *arguments_gc_map; // should be assigned the value of "f_arguments_gc_map"
int *arguments_base_address; // address of the first argument
char *locals_gc_map; // should be assigned the value of "f_locals_gc_map"
struct A *local1; // remaining fields are method locals
int local2;
struct C *local3;
};
Exercise 6.
Modify your current code generation part for methods (file
codegen.C.PrettyPrintVisitor.java), to generate and
print
out a GC stack frame, one for each method (a C struct definition,
just like the data
structure above).
f looks like:
// a global pointer
void *prev;
// two memory GC maps "f_arguments_gc_maps" and "f_locals_gc_maps" for this function, as above
// one data structure "f_gc_frame" for GC stack frame, as above
T f (D this, int arg1, A arg2, B arg3){
// put the GC stack frame onto the call stack
// note that this frame contains the three original locals in f
struct f_gc_frame frame;
// push this frame onto the GC stack by setting up "prev"
frame.prev = prev;
prev = &frame;
// setting up memory GC maps and corresponding base addresses
frame.arguments_gc_map = f_arguments_gc_map;
frame.arguments_base_address = &this;
frame.locals_gc_map = f_locals_gc_map;
// initialize locals of this method
... // statements should be rewritten apporpriately
}
Exercise 7.
Modify you code generation and pretty printer for
methods in the C code generator, to generate and print
GC stack frame for each method. Don't forget to modify
the generated code for statements to use the new locals.
And also don't forget to pop off the GC stack frame
just before the return statement.
Exercise 8. You should have noted that, essentially, you need NOT put all locals onto the GC stack frame, but just those locals of reference types. (Why?) Modify your current code generator again to implement this improvement: to put locals of reference types onto the GC stack but others onto the C call stack. This may also simplify the stack GC maps data structures for locals, which could be an integer indicating the number of reference-typed locals, instead of a bit-vector.
Challenge! The memory GC maps data structure you have been using so far is a bit-vector, which is easy to generate but may waste space for functions that have many arguments (or locals) but among which few are references. What's the length of the bit-vector? How many 1s are there in the bit-vector? Design a more compact data structure representation for memory GC maps, and try to implement your data structure into your Tiger compiler.
Challenge! Suppose that if you are using a C compiler which makes use of different calling convention from the one you've implemented, say, the order of the arguments on the call stack are different. Or suppose that you are generating code for a different ISA (say, ARM or MIPS) on which arguments are passed via registers (along with call stack). Try to design a universal memory GC maps data structure which can handle all of these, and try to implement your idea into your Tiger compiler.
Class GC Maps
For each class, you need to generate a class GC map data structure specifying the number of fields this class has and among those which are references. You can also use the bit-vector representation except for that you should store the generated bit-vector into the class's virtual method table. That is, the virtual method table for each class will contain a class GC map field, as in:
struct A_virtual_table{
char *A_gc_map; // class GC map
... // virtual methods as before
};
Exercise 9. Modify the code generation and pretty printing code to generate class GC maps (in bit-vector form), one for each class. You should store the class GC map in the first field of the class' virtual method table.
Part B: Copying Collection
In this part of the lab, you will write the Gimple garbage collector. You will first design and implement a Java heap, then you will design an object model, finally you will implement a copying collection algorithm based on Cheney's.The Java Heap
In the previous lab, for simplicity, you have stored all Java objects into the C heap (using C librarymalloc) directly, though
easy to understand and implement, this method has serious
drawbacks, especially, it's hard, if not impossible, to
reclaim dead objects in an automatic way. So, in this part
of the lab, you will first design a data structure to implement
a Java heap. As you will use copying collection in your Gimple GC, so
the heap consists of two semi-heap of equal sizes.
Exercise 10.
You can find the data structure JavaHeap for the Java heap
in the file runtime/gc.c. Read that data structure
definition and fill in the function Tiger_heap_init()
which will initialize the heap variable. Note that
the Tiger_heap_init() function is called by
function main() in file main.c.
Object Model
An object model is the strategy that how an object can be laid out in memory (the heap). A good object model should support all kinds of possible operations efficiently on an object: virtual method dispatching, locking, garbage collection, etc., whereas at the same time be as compact as possible to save storage.In the previous lab, you have used a simple yet standard object model. As there are two different forms of objects in MiniJava: normal objects and (integer) array objects. So, to support virtual method dispatching on normal objects, each object is represented as a sequence of its fields plus a unique virtual method table pointer at the zero offset as a header. And to support array length operations on array objects, arrays contain a length field as a header. However, to support garbage collection, you need a much fancier object model.
For both normal objects and array objects, you can
use the following object model (suppose the class
name is A):
struct A_class{
void *vptr; // virtual method table pointer
int isObjOrArray; // is this a normal object or an (integer) array object?
unsigned length; // array length
void *forwarding; // forwarding pointer, will be used by your Gimple GC
...; // remainings are normal class or array fields
};
So an object will have an object header with 4 machine words: the first
field vptr is a virtual method table pointer pointing
to the class virtual method table, to
support virtual method dispatching; the second field isObjOrArray
denotes whether the current object is a normal object or is an
array object; the third field length records
the length of the array (if the current object is indeed
an array); finally, the fourth field forwarding
is a special pointer which will be used by your Gimple GC
next. Following the object header are normal class or array
fields.
Exercise 11.
Modify the code in
functions Tiger_new(), Tiger_new_array() in the
file runtime/gc.c, to use this new object
model. Don't forget to change your code generation part of
your Tiger compiler to reflect the
change of the object model.
Challenge! The object model you have been using so far, though simple and illustrative, may waste too much space for small objects due to the relatively large object header. Design and implement a fancier object model to reduce the size of the header. Can you use just one machine word, instead of 4 machine words?
Challenge! Design an object model to support all Java (not MiniJava) features: virtual method dispatching, multi-threading, locking, garbage collection, and hashing. You can start by taking a look at this article and this paper.
Copying Collection
Finally, you are going to write the Gimple collector code. The algorithm you will use is the Cheney's algorithm which uses a breadth-first strategy. If you haven't read the algorithm, you should read Tiger book chapter 13.3 first. Make sure you understand Cheney's algorithm thoroughly before continuing.Exercise 12.
Implement the copying collector in the function
Tiger_gc() in the file
runtime/gc.c. Recall that you can use the prev
pointer to trace all roots (roots are in the GC stack).
Challenge! The current GC stack, though correct and simple, is somewhat imprecise in describing current live objects. To understand this, consider the following Java code:
1: void f(){
2: A x = new A();
3: A y = new A();
4: return 0;
5: }
suppose that the GC occurs during the object allocation at
line 3, the current GC stack used in your Gimple will mark
the object x at line 2 alive and thus doesn't
reclaim its heap space. However, as you can see from the
code, the object x will never be used after
line 2, which can be collected in line 3. Propose another
more precise method to mark live objects. You may want to read
this paper to start with.
Challenge! Though you have implemented the breadth-first Cheney's algorithm, there are other approaches for a copying-based collection. For instance, the Tiger book also introduces depth-first traversal of the Java heap. And difference design decision has a direct impact on the performance of the garbage collector.
Will a depth-first scanning into the heap run faster than a breadth-first one? You may want to take a look at Garner's thesis for some experimental results. And you may want to write a depth-first collector for your Tiger compiler to do some comparisions..
Exercise 13. Typically, the Gimple GC runs silently behind the application. In order to understand its behaviour better, you can instrument your GC to output some statistical information. For instance, when your application runs, besides the normal output, your Gimple GC can also output a log file with contents like this:
1 round of GC: 0.3s, collected 512 bytes
2 round of GC: 0.2s, collected 128 bytes
3 round of GC: 0.8s, collected 4096 bytes
which indicates that during the execution of your application, there
are totally 3 rounds of GC happened (with the GC time and
heap spaces reclaimed). Implement this logging feature
into you Gimple GC. You should modify the function
Tiger_gc along with the function main()
in file main.c. And this feature should be
controlled by a command line argument, so you would like
to take a look at files control.c and
command-line.c.
Challenge! Here are some ideas to improve your current Gimple GC: