作业提交电子版本,提交到bb系统(https://www.bb.ustc.edu.cn)上
作业答案
Coursework 第一次作业
第二版书:
- 3.7 (a, b, d)
- 3.9
Deadline: 2024年3月18日
3.7 Give the initial state, goal test, successor function, and cost function for each of the following. Choose a formulation that is precise enough to be implemented.
a. You have to color a planar map using only four colors, in such a way that no two adjacent regions have the same color.
b. A 3-foot-tall monkey is in a room where some bananas are suspended from the 8-foot ceiling. He would like to get the bananas. The room contains two stackable, movable, climbable 3-foot-high crates.
c. You have a program that outputs the message “illegal input record” when fed a certain file of input records. You know that processing of each record is independent of the other records. You want to discover what record is illegal.
d. You have three jugs, measuring 12 gallons, 8 gallons, and 3 gallons, and a water faucet. You can fill the jugs up or empty them out from one to another or onto the ground. You need to measure out exactly one gallon.
3.9 The missionaries and cannibals problem is usually stated as follows. Three missionaries and three cannibals are on one side of a river, along with a boat that can hold one or two people. Find a way to get everyone to the other side without ever leaving a group of missionaries in one place outnumbered by the cannibals in that place. This problem is famous in AI because it was the subject of the first paper that approached problem formulation from an analytical viewpoint (Amarel, 1968).
a. Formulate the problem precisely, making only those distinctions necessary to ensure a valid solution. Draw a diagram of the complete state space.
b. Implement and solve the problem optimally using an appropriate search algorithm. Is it a good idea to check for repeated states?
c. Why do you think people have a hard time solving this puzzle, given that the state space is so simple?
3.7 给出下列问题的初始状态、目标测试、后继函数和耗散函数。选择精确得足以实现的形式化。
a. 只用四种颜色对平面地图染色,要求每两个相邻的地区不能染成相同的颜色。
b. 一间屋子里有一只3英尺高的猴子,屋子的房顶上挂着一串香蕉,离地面8英尺。屋子里有两个可叠放起来、可移动、可攀登的3英尺高的箱子。猴子很想得到香蕉。
c. 有一个程序,当送入一个特定文件的输入记录时会输出“不合法的输入记录”。已知每个记录的处理独立于其它记录。要求找出哪个记录不合法。
d. 有三个水壶,容量分别为12加仑、8加仑和3加仑,还有一个水龙头。可以把壶装满或者倒空,从一个壶倒进另一个壶或者倒在地上。要求量出刚好1加仑水。
3.9 传教士和野人问题通常描述如下:三个传教士和三个野人在河的一边,还有一条能载一个人或者两个人的船。找到一个办法让所有的人都渡到河的另一岸,要求在任何地方野人数都不能多于传教士的人数(可以只有野人没有传教士)。这个问题在AI领域中很著名,因为它是第一篇从分析的观点探讨问题形式化的论文的主题(Amarel, 1968)
a. 精确地形式化该问题,只描述确保该问题有解所必需的特性。画出该问题的完全状态空间图。
b. 用一个合适的搜索算法实现和最优地求解该问题。检查重复状态是个好主意吗?
c. 这个问题的状态空间如此简单,你认为为什么人们求解它却很困难?
Coursework 第二次作业
第二版书:
- 4.1
- 4.2
- 4.6
- 4.7
Deadline: 2024年3月25日
4.1 Trace the operation of $A^*$ search applied to the problem of getting to Bucharest from Lugoj using the straight-line distance heuristic. That is, show the sequence of nodes that the algorithm will consider and the $f , g$, and $h$ score for each node.
4.2 The heuristic path algorithm is a best-first search in which the objective function is $f ( n ) = (2 - w)g(n) + wh(n)$. For what values of w is this algorithm guaranteed to be optimal? (You may assume that h is admissible.) What kind of search does this perform when $w = 0$? When$ w = 1$?When $w = 2$?
4.6 Invent a heuristic function for the 8-puzzle that sometirnes overestimates, and show how it can lead to a suboptimal solution on a particular problem. (You can use a computer to help if you want.) Prove that, if $h$ never overestimates by more than $c, A^*$ using $h$ returns a solution whose cost exceeds that of the optimal solution by no more than $c$.
4.7 Prove that if a heuristic is consistent, it must be admissible. Construct an admissible heuristic that is not consistent.
4.1 跟踪$A^*$搜索算法用直线距离启发式求解从Lugoj到Bucharest问题的过程。按顺序列出算法扩展的节点和每个节点的$f,g,h$值。
4.2 启发式路径算法是一个最佳优先搜索,它的目标函数是$f ( n ) = (2 - w)g(n) + wh(n)$。算法中$w$取什么值能保证算法是最优的?当$w=0$时,这个算法是什么搜索?$w=1$呢?$w=2$呢?
4.6 设计一个启发函数,使它在八数码游戏中有时会估计过高,并说明它在什么样的特殊问题下会导致次最优解。(可以借助计算机的帮助。)证明:如果$h$被高估的部分从来不超过$c,A^*$算法返回的解的耗散比最优解的耗散多出的部分也不超过$c$。
4.7 证明如果一个启发式是一致的,它肯定是可采纳的。构造一个非一致的可采纳启发式。
Coursework 第三次作业
第三版书:
- 6.5
- 6.11
- 6.12
Deadline: 2024年4月1日
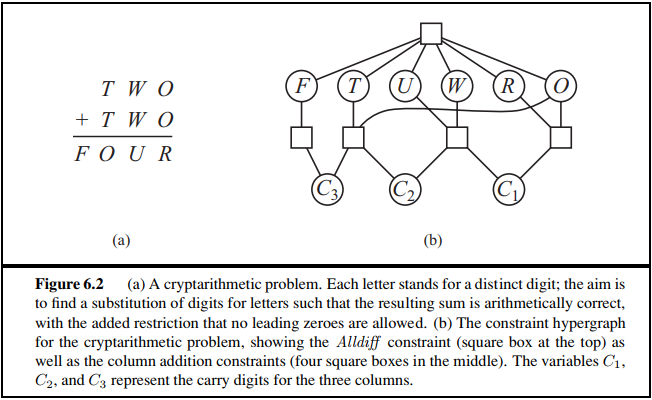
6.5 Solve the cryptarithmetic problem in Figure 6.2 by hand, using the strategy of backtracking with forward checking and the MRV and least-constraining-value heuristics respectively.
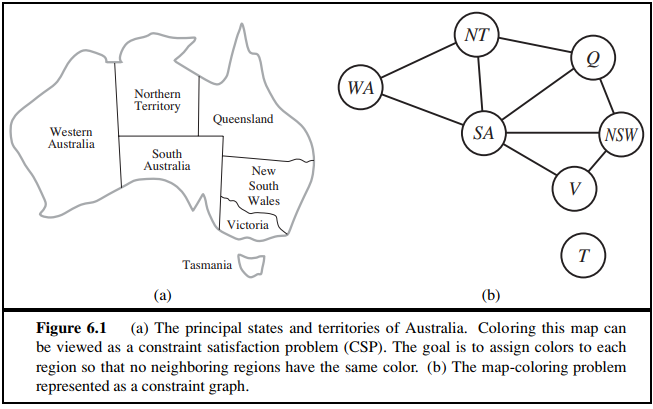
6.11 Use the AC-3 algorithm to show that arc consistency can detect the inconsistency of the partial assignment ${WA = green, V = red}$ for the problem shown in Figure 6.1
6.12 What is the worst-case complexity of running AC-3 on a tree-structured CSP?
6.5 分别用带有前向检验、MRV和最少约束值启发式的回溯算法手工求解图6.2中的密码算数问题。
6.11 用AC-3算法说明弧相容对图6.1中问题能够检测出部分赋值${WA =green,V= red}$的不相容。
6.12 用AC-3算法求解树结构CSP在最坏情况下的复杂度是多少?
Coursework 第四次作业
第三版书:
- 5.9
- 5.8
- 5.13
Deadline: 2024年4月9日
5.9 This problem exercises the basic concepts of game playing, using tic-tac-toe (noughts and crosses) as an example. We define $X_n$ as the number of rows, columns, or diagonals with exactly $n\ X’s$ and no $O’s$. Similarly, $O_n$ is the number of rows, columns, or diagonals with just $n\ O’s$. The utility function assigns$ +1$ to any position with $X_3 = 1$ and $-1$ to any position with $O_3 = 1$. All other terminal positions have utility 0. For nonterminal positions, we use a linear evaluation function defined as $Eval(s) = 3X_2(s)+X_1(s)-(3O_2(s)+O_1(s))$.
a. Approximately how many possible games of tic-tac-toe are there?
b. Show the whole game tree starting from an empty board down to depth 2 (i.e., one $X$ and one $O$ on the board), taking symmetry into account.
c. Mark on your tree the evaluations of all the positions at depth 2.
d. Using the minimax algorithm, mark on your tree the backed-up values for the positions at depths 1 and 0, and use those values to choose the best starting move.
e. Circle the nodes at depth 2 that would not be evaluated if alpha–beta pruning were applied, assuming the nodes are generated in the optimal order for alpha–beta pruning.
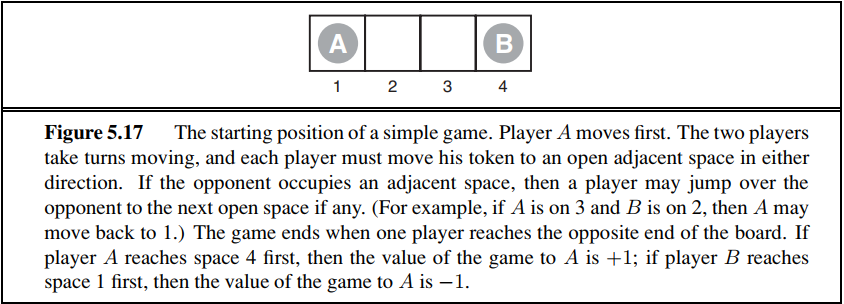
5.8 Consider the two-player game described in Figure 5.17.
a. Draw the complete game tree, using the following conventions:
Write each state as $(s_A, s_B)$, where $s_A$ and $s_B$ denote the token locations.
Put each terminal state in a square box and write its game value in a circle.
Put loop states (states that already appear on the path to the root) in double square boxes. Since their value is unclear, annotate each with a “?” in a circle.
b. Now mark each node with its backed-up minimax value (also in a circle). Explain how you handled the “?” values and why.
c. Explain why the standard minimax algorithm would fail on this game tree and briefly sketch how you might fix it, drawing on your answer to (b). Does your modified algorithm give optimal decisions for all games with loops?
d. This 4-square game can be generalized to n squares for any $n > 2$. Prove that $A$ wins if $n$ is even and loses if $n$ is odd.
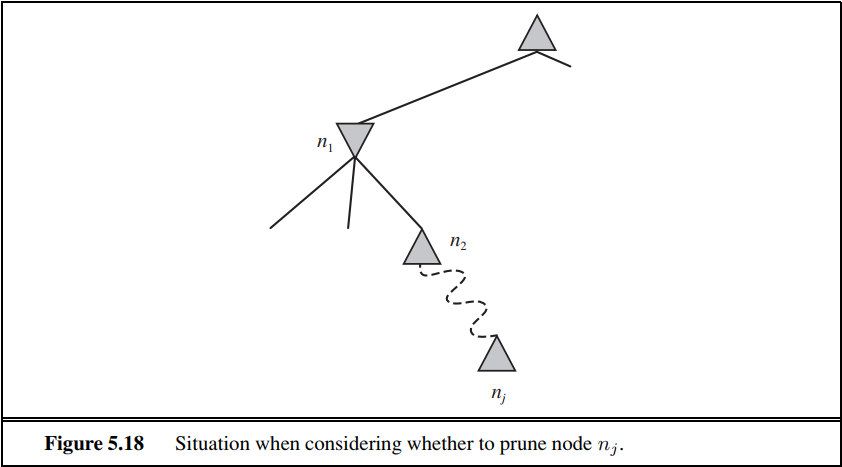
5.13 Develop a formal proof of correctness for alpha–beta pruning. To do this, consider the situation shown in Figure 5.18. The question is whether to prune node $n_j$, which is a maxnode and a descendant of node $n_1$. The basic idea is to prune it if and only if the minimax value of $n_1$ can be shown to be independent of the value of $n_j$.
a. Mode $n_1$ takes on the minimum value among its children: $n_1 = min(n_2, n_{21}, . . . , n_2b_2)$. Find a similar expression for $n_2$ and hence an expression for $n_1$ in terms of $n_j$.
b. Let $l_i$ be the minimum (or maximum) value of the nodes to the left of node $n_i$ at depth $i$, whose minimax value is already known. Similarly, let $r_i$ be the minimum (or maximum) value of the unexplored nodes to the right of $n_i$ at depth $i$. Rewrite your expression for $n_1$ in terms of the $l_i$ and $r_i$ values.
c. Now reformulate the expression to show that in order to affect $n_1, n_j$ must not exceed a certain bound derived from the $l_i$ values.
d. Repeat the process for the case where $n_j$ is a min-node.
5.9 本题以井字棋(圈与十字游戏)为例练习博弈中的基本概念。定义$X_n$为恰好有$n$个$X$而没有$O$的行、列或者对角线的数目。同样$O_n$为正好有$n$个$O$的行、列或者对角线的数目。效用函数给$X_3=1$的棋局$+1$,给$O_3=1$的棋局$-1$。所有其他终止状态效用值为$0$。对于非终止状态,使用线性的评估函数定义为$Eval(s) = 3X_2(s)+X_1(s)-(3O_2(s)+O_1(s))$。
a. 估算可能的井字棋局数。
b. 考虑对称性,给出从空棋盘开始的深度为2的完整博弈树(即,在棋盘上一个$X$一个$O$的棋局)。
c. 标出深度为2的棋局的评估函数值。
d. 使用极小极大算法标出深度为1和0的棋局的倒推值,并根据这些值选出最佳的起始行棋。
e. 假设结点按对$\alpha-\beta$剪枝的最优顺序生成,圈出使用$\alpha-\beta$剪枝将被剪掉的深度为2的结点。
5.8 考虑图5.17中描述的两人游戏。
a. 根据如下约定画出完整博弈树:
每个状态用$(s_A, s_B)$表示,其中 $s_A$和$s_B$表示棋子的位置。
每个终止状态用方框画出,用圆圈写出它的博弈值。
把循环状态(在到根结点的路径上已经出现过的状态)画上双层方框。由于不清楚他们的值,在圆圈里标记一个“? ”。
b. 给出每个结点倒推的极小极大值(也标记在圆圈里)。解释怎样处理“?”值和为什么这么处理。
c. 解释标准的极小极大算法为什么在这棵博弈树中会失败,简要说明你将如何修正它,在(b)的图上画出你的答案。你修正后的算法对于所有包含循环的游戏都能给出最优决策吗?
d. 这个4-方格游戏可以推广到$n$个方格,其中$n>2$。证明如果$n$是偶数$A$一定能赢,而$n$是奇数则$A$一定会输。
5.13 请给出$\alpha-\beta$剪枝正确性的形式化证明。要做到这一点需考虑图5.18。问题为是否要剪掉结点$n_j$,它是一个MAX结点,是$n_1$的一个后代。基本的思路是当且仅当$n_1$的极小极大值可以被证明独立于$n_j$的值时,会发生剪枝。
a. $n_1$的值是所有后代结点的最小值: $n_1 = min(n_2, n_{21}, . . . , n_2b_2)$请为$n_2$找到类似的表达式,以得到用$n_j$表示的$n_1$的表达式。
b. 深度为$i$的结点$n_i$的极小极大值已知,$l_i$是在结点$n_i$左侧结点的极小值(或者极大值)。同样,$r_i$是在$n_i$右侧的未探索过的结点的极小值(或者极大值)。用$l_i$和$r_i$的值重写$n_1$的表达式。
c. 现在重新形式化表达式,来说明为了向$n_1$施加影响,$n_j$不能超出由$l_i$值得到的某特定界限。
d. 假设$n_j$是MIN结点的情况,请重复上面的过程。
Coursework 第五次作业
- 第三版书:7.13
- Proof
Deadline: 2024年4月18日
7.13 This exercise looks into the relationship between clauses and implication sentences.
a. Show that the clause $(\neg P_1\lor…\lor\neg{P_m}\lor{Q})$ is logically equivalent to the implication sentence.$(P_1\land\dots\land{P_m})\Rightarrow{Q}$
b. Show that every clause (regardless of the number of positive literals) can be written in the form $(P_1\land\dots\land{P_m})\Rightarrow{(Q_q\lor\dots\lor{Q_n})}$, where the $P_s$ and $Q_s$ are proposition symbols. A knowledge base consisting of such sentences is in implicative normal form or Kowalski form (Kowalski, 1979).
c. Write down the full resolution rule for sentences in implicative normal form.
Proof. Prove the completeness of the forward chaining algorithm.
7.13 本题考察子句和蕴含语句之间的关系。
a. 证明子句$(\neg P_1\lor…\lor\neg{P_m}\lor{Q})$逻辑等价于蕴含语句$(P_1\land\dots\land{P_m})\Rightarrow{Q}$。
b. 证明每个子句(不管正文字的数量)都可以写成$(P_1\land\dots\land{P_m})\Rightarrow{(Q_q\lor\dots\lor{Q_n})}$的形式,其中$P_i$和$O_i$都是命题词。由这类语句构成的知识库是表示为蕴含范式或称Kowalski)范式(Kowalski,1979)。
c. 写出蕴含范式语句的完整归结规则。
证明. 证明前向链接算法的完备性。
Coursework 第六次作业
第三版书:
- 8.24 (a-k), 8.17
- 9.3, 9.4, 9.6, 9.13(a,b,c)
Deadline: 2024年4月28日
8.24 Represent the following sentences in first-order logic, using a consistent vocabulary(which you must define):
a. Some students took French in spring 2001.
b. Every student who takes French passes it.
c. Only one student took Greek in spring 2001.
d. The best score in Greek is always higher than the best score in French.
e. Every person who buys a policy is smart.
f. No person buys an expensive policy.
g. There is an agent who sells policies only to people who are not insured.
h. There is a barber who shaves all men in town who do not shave themselves.
i. A person born in the UK, each of whose parents is a UK citizen or a UK resident, is a UK citizen by birth.
j. A person born outside the UK, one of whose parents is a UK citizen by birth, is a UK citizen by descent.
k. Politicians can fool some of the people all of the time, and they can fool all of the people some of the time, but they can’t fool all of the people all of the time.
8.17 Explain what is wrong with the following proposed definition of adjacent squares in the wumpus world:
$$
\forall x,y\ \ \ \ Adjacent([x,y],[x+1,y])\land Adjacent([x,y],[x,y+1]).
$$
9.3 Suppose a knowledge base contains just one sentence, $\exists x\ AsHighAs(x, Everest)$. Which of the following are legitimate results of applying Existential Instantiation?
a. $AsHighAs(Everest, Everest)$.
b. $AsHighAs(Kilimanjaro, Everest)$.
c. $AsHighAs(Kilimanjaro, Everest) \land AsHighAs(BenNevis, Everest)$ (after two applications).
9.4 For each pair of atomic sentences, give the most general unifier if it exists:
a. $P(A, B, B), P(x, y, z)$.
b. $Q(y, G(A, B)), Q(G(x, x), y)$.
c. $Older(Father(y), y), Older(Father(x), John)$.
d. $Knows(Father(y), y), Knows(x, x)$.
9.6 Write down logical representations for the following sentences, suitable for use with Generalized Modus Ponens:
a. Horses, cows, and pigs are mammals.
b. An offspring of a horse is a horse.
c. Bluebeard is a horse.
d. Bluebeard is Charlie’s parent.
e. Offspring and parent are inverse relations.
f. Every mammal has a parent.
9.13 In this exercise, use the sentences you wrote in Exercise 9.6 to answer a question by using a backward-chaining algorithm.
a. Draw the proof tree generated by an exhaustive backward-chaining algorithm for the query $\exists h\ Horse(h)$, where clauses are matched in the order given.
b. What do you notice about this domain?
c. How many solutions for $h$ actually follow from your sentences?
8.24 用一个相容的词汇表(需要你自己定义)在一阶逻辑中表示下列语句:
a. 某些学生在2001年春季学期上法语课。
b. 上法语课的每个学生都通过了考试。
c. 只有一个学生在2001年春季学期上希腊语课。
d. 希腊语课的最好成绩总是比法语课的最好成绩高。
e. 每个买保险的人都是聪明的。
f. 没有人会买昂贵的保险。
g. 有一个代理,他只卖保险给那些没有投保的人。
h. 镇上有一个理发师,他给所有不自己刮胡子的人刮胡子。
i. 在英国出生的人,如果其双亲都是英国公民或永久居住者,那么此人生来就是一个英国公民。
j. 在英国以外的地方出生的人,如果其双亲生来就是英国公民,那么此人血统上是一个英国公民。
k. 政治家可以一直愚弄某些人,也可以在某个时候愚弄所有人,但是他们无法一直愚弄所有的人。
8.17 解释下面给出的 Wumpus世界中相邻方格的定义存在什么问题:
$$
\forall x,y\ \ \ \ Adjacent([x,y],[x+1,y])\land Adjacent([x,y],[x,y+1]).
$$
9.3 假定知识库中只包括一条语句:$\exists x\ AsHighAs(x, Everest)$。下列那个语句是应用存在量词实例化以后的合法结果?
a. $AsHighAs(Everest, Everest)$.
b. $AsHighAs(Kilimanjaro, Everest)$.
c. $AsHighAs(Kilimanjaro, Everest) \land AsHighAs(BenNevis, Everest)$ (在两次应用之后).
9.4 对于下列每对原子语句,如果存在,请给出最一般合一置换:
a. $P(A, B, B), P(x, y, z)$.
b. $Q(y, G(A, B)), Q(G(x, x), y)$.
c. $Older(Father(y), y), Older(Father(x), John)$.
d. $Knows(Father(y), y), Knows(x, x)$.
9.6 写出下列语句的逻辑表示,使得它们适用一般化假言推理规则:
a. 马、奶牛和猪都是哺乳动物。
b. 一匹马的后代是马。
c. Bluebeard是一匹马。
d. Bluebeard是 Charlie的家长。
e. 后代和家长是逆关系。
f. 每个哺乳动物都有一个家长。
9.13 本题中需要用到你在习题9.6中写出的语句,运用反向链接算法来回答问题。
a. 画出用穷举反向链接算法为查询$\exists h\ Horse(h)$生成的证明树,其中子句按照给定的顺序进行匹配。
b. 对于本领域,你注意到了什么?
c. 实际上从你的语句中得出了多少个$h$的解?
Coursework 第七次作业
第三版书:
- 13.15, 13.18, 13.21, 13.22, 14.12, 14.13
Deadline: 2024年5月12日

13.15 After your yearly checkup, the doctor has bad news and good news. The bad news is that you tested positive for a serious disease and that the test is 99% accurate (i.e., the probability of testing positive when you do have the disease is 0.99, as is the probability of testing negative when you don’t have the disease). The good news is that this is a rare disease, striking only 1 in 10,000 people of your age. Why is it good news that the disease is rare? What are the chances that you actually have the disease?
13.18 Suppose you are given a bag containing $n$ unbiased coins. You are told that $n - 1$ of these coins are normal, with heads on one side and tails on the other, whereas one coin is a fake, with heads on both sides.
a. Suppose you reach into the bag, pick out a coin at random, flip it, and get a head. What is the (conditional) probability that the coin you chose is the fake coin?
b. Suppose you continue flipping the coin for a total of $k$ times after picking it and see k heads. Now what is the conditional probability that you picked the fake coin?
c. Suppose you wanted to decide whether the chosen coin was fake by flipping it $k$ times. The decision procedure returns $fake$ if all $k $ flips come up heads; otherwise it returns $normal$. What is the (unconditional) probability that this procedure makes an error?
13.21 (Adapted from Pearl (1988).) Suppose you are a witness to a nighttime hit-and-run accident involving a taxi in Athens. All taxis in Athens are blue or green. You swear, under oath, that the taxi was blue. Extensive testing shows that, under the dim lighting conditions, discrimination between blue and green is 75% reliable.
a. Is it possible to calculate the most likely color for the taxi? (Hint: distinguish carefully between the proposition that the taxi is blue and the proposition that it $appears$ blue.)
b. What if you know that 9 out of 10 Athenian taxis are green?
13.22 Text categorization is the task of assigning a given document to one of a fixed set of categories on the basis of the text it contains. Naive Bayes models are often used for this task. In these models, the query variable is the document category, and the “effect” variables are the presence or absence of each word in the language; the assumption is that words occur independently in documents, with frequencies determined by the document category.
a. Explain precisely how such a model can be constructed, given as “training data” a set of documents that have been assigned to categories.
b. Explain precisely how to categorize a new document.
c. Is the conditional independence assumption reasonable? Discuss.
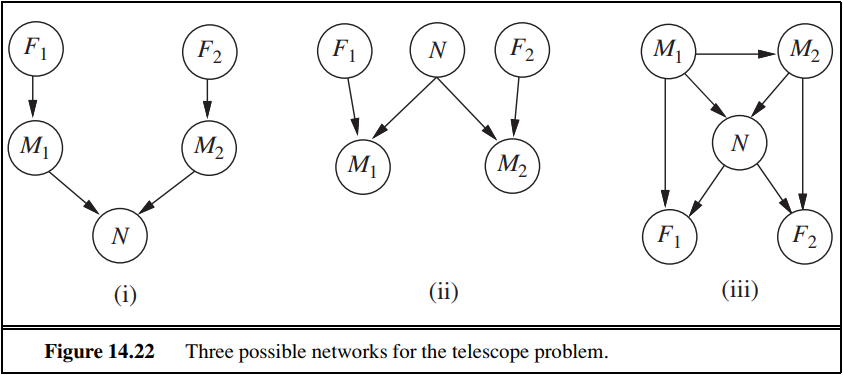
14.12 Two astronomers in different parts of the world make measurements $M_1$ and $M_2$ of the number of stars $N$ in some small region of the sky, using their telescopes. Normally, there is a small possibility $e$ of error by up to one star in each direction. Each telescope can also (with a much smaller probability $f$) be badly out of focus (events $F_1$ and $F_2$), in which case the scientist will undercount by three or more stars (or if $N$ is less than $3$, fail to detect any stars at all). Consider the three networks shown in Figure 14.22.
a. Which of these Bayesian networks are correct (but not necessarily efficient) representations of the preceding information?
b. Which is the best network? Explain.
c. Write out a conditional distribution for $\textbf{P}(M_1 | N)$, for the case where $N\in {1, 2, 3}$ and $M_1 \in {0, 1, 2, 3, 4}$. Each entry in the conditional distribution should be expressed as a function of the parameters $e$ and/or $f$.
d. Suppose $M_1 = 1$ and $M_2 = 3$. What are the possible numbers of stars if you assume no prior constraint on the values of $N$?
e. What is the most likely number of stars, given these observations? Explain how to compute this, or if it is not possible to compute, explain what additional information is needed and how it would affect the result.
14.13 Consider the network shown in Figure 14.22(ii), and assume that the two telescopes work identically. $N \in {1, 2, 3} $and $M_1, M_2 \in {0, 1, 2, 3, 4}$, with the symbolic CPTs as described in Exercise 14.12. Using the enumeration algorithm (Figure 14.9 on page 525), calculate the probability distribution $\textbf{P}(N | M_1 = 2, M_2 = 2)$.
13.15 在一年一度的体检之后,医生告诉你一些坏消息和一些好消息。坏消息是你在一种严重疾病的测试中结果呈阳性,而这个测试的准确度为99%(即当你确实患这种病时,测试结果为阳性的概率为0.99;而当你未患这种疾病时测试结果为阴性的概率也是0.99)。好消息是,这是一种罕见的病,在你这个年龄段大约10000人中才有1例。为什么“这种病很罕见”对于你而言是一个好消息?你确实患有这种病的概率是多少?
13.18 假设给你一只袋子,装有$n$个无偏差的硬币,并且告诉你其中$n - 1$个硬币是正常的,一面是正面而另一面是反面。不过剩余1枚硬币是伪造的,它的两面都是正面。
a. 假设你把手伸进口袋均匀随机地取出一枚硬币,把它抛出去,硬币落地后正面朝上。那么你取出伪币的(条件)概率是多少?
b. 假设你不停地抛这枚硬币,一共抛了$k$次,而且看到$k$次正面向上。那么你取出伪币的条件概率是多少?
c. 假设你希望通过把取出的硬币抛$k$次的方法来确定它是不是伪造的。如果抛$k$次后都是正面朝上,那么决策过程返回$fake$(伪造),否则返回$normal$(正常)。这个过程发生错误的((无条件)概率是多少?
13.21 (改编自Pearl (1988)的著述。)假设你是雅典一次夜间出租车肇事逃逸的交通事的目击者。雅典所有的出租车都是蓝色或者绿色的。而你发誓所看见的肇事出租车是蓝色的。大量测试表明,在昏暗的灯光条件下,区分蓝色和绿色的可靠度为75%。
a. 有可能据此计算出肇事出租车最可能是什么颜色吗?(提示:请仔细区分命题“肇事车是蓝色的”和命题“肇事车看起来是蓝色的”。)
b. 如果你知道雅典的出租车10辆中有9辆是绿色的呢?
13.22 文本分类是基于文本内容将给定的一个文档分类成固定的几个类中的一类。朴素贝叶斯模型经常用于这个问题。在朴素贝叶斯模型中,查询(query)变量是这个文档的类别,而结果(effect)变量是语言中每个单词的存在与否;假设文档中单词的出现是独立的,单词的出现频率由文档类别决定。
a. 给定一组已经被分类的文档,准确解释如何构造这样的模型。
b. 准确解释如何分类一个新文档。
c. 题目中的条件独立性假设合理吗?请讨论。
14.12 两个来自世界上不同地方的宇航员同时用他们自己的望远镜观测了太空中某个小区域内恒星的数目$N$。他们的测量结果分别为$M_1$和$M_2$。通常,测量中会有不超过1颗恒星的误差,发生错误的概率$e$很小。每台望远镜可能出现(出现的概率$f$更小一些)对焦不准确的情况(分别记作$F_1$和$F_2$),在这种情况下科学家会少数三颗甚至更多的恒星(或者说,当$N$小于3时,连一颗恒星都观测不到)。考虑图14.22所示的三种贝叶斯网络结构。
a. 这三种网络结构哪些是对上述信息的正确(但不一定高效)表示?
b.哪一种网络结构是最好的?请解释。
c.当$N\in {1, 2, 3}$,$M_1 \in {0, 1, 2, 3, 4}$时,请写出$\textbf{P}(M_1 | N)$的条件概率表。概率分布表里的每个条目都应该表达为参数$e$和或$f$的一个函数。
d.假设$M_1 = 1$,$M_2 = 3$。如果我们假设$N$取值上没有先验概率约束,可能的恒星数目是多少?
e.在这些观测结果下,最可能的恒星数目是多少?解释如何计算这个数目,或者,如果不可能计算,请解释还需要什么附加信息以及它将如何影响结果。
14.13 考虑 图14.22(ii) 的网络,假设两个望远镜完全相同。$N \in {1, 2, 3} $,$M_1, M_2 \in {0, 1, 2, 3, 4}$,CPT表和习题14.12所描述的一样。使用枚举算法(图14.9)计算概率分布$\textbf{P}(N | M_1 = 2, M_2 = 2)$。
Coursework 第八次作业
Deadline: 2024年5月31日
1.试证明对于不含冲突数据集(即特征向量完全相同但标记不同)的训练集,必存在与训练集一致(即训练误差为 0)的决策树。
2.最小二乘学习方法在求解 $min_w(Xw-y)^2$ 问题后得到闭式解 $w^*=(X^TX)^{-1}X^Ty$ (为简化问题,我们忽略偏差项 $b$)。如果我们知道数据中部分特征有较大的误差,在不修改损失函数的情况下,引入规范化项 $\lambda w^TDw$ ,其中 $D$ 为对角矩阵,由我们取值。相应的最小二乘分类学习问题转换为以下形式的优化问题:
$min_w(Xw-y)^2+\lambda w^TDw$
(1).请说明选择规范化项 $w^TDw$ 而非 $L2$ 规范化项 $w^Tw$ 的理由是什么。$D$ 的对角线元素 $D_{ii}$ 有何意义,它的取值越大意味着什么?
(2).请对以上问题进行求解。
3.假设有 $n$ 个数据点 $x_1, \dots, x_n$ 以及一个映射 $\varphi :x \rightarrow \varphi(x)$ ,以此定义核函数 $K(x, x^{\prime})=\varphi(x) \cdot \varphi(x^{\prime})$ 。试证明由该核函数所决定的核矩阵 $K:\ K_{i,j}=K(x_i, x_j)$ 有以下性质:
(1). $K$ 是一个对称矩阵;
(2). $K$ 是一个半正定矩阵,即 $\forall z \in R^n, z^TKz \geq 0$ 。
4.已知正例点$x_1=(1,2)^T, x_2=(2,3)^T, x_3=(3,3)^T$,负例点$x_4=(2,1)^T, x_5=(3,2)^T$,试求Hard Margin SVM的最大间隔分离超平面和分类决策函数,并在图上画出分离超平面、间隔边界及支持向量。
5.计算$\frac{\partial}{\partial w_j}L_{CE}(w,b)$,其中
$L_{CE}(w,b)=-[y\ log\sigma(w\cdot x + b) + (1-y)\ log(1-\sigma(w\cdot x + b))]$
为Logistic Regression的Loss Function。
已知
$\frac{\partial}{\partial z}\sigma(z)=\frac{\partial}{\partial z}\frac{1}{1+e^{-z}}=-(\frac{1}{1+e^{-z}})^2 \times (-e^{-z})$
$=\sigma^2(z)(\frac{1-\sigma(z)}{\sigma(z)})=\sigma(z)(1-\sigma(z))$
6.$K-means$ 算法是否一定会收敛? 如果是,给出证明过程;如果不是,给出说明