*Yong Xu, Jun Du, Li-Rong Dai and Chin-Hui LEE, Fellow, IEEE
E-mail: xuyong62@mail.ustc.edu.cn, *Yong Xu
Section 1: More enhanced speech demos based on Deep neural networks
Section 2: Related waveforms refered in the submitted paper
Section 1: More enhanced speech demos based on Deep neural networks
Selected results on some unseen noise types at the common SNRs (10dB, 5dB):
Improved DNN |
LogMMSE |
Noisy |
Clean |
|
| Machine gun, SNR10 | ||||
| Machine gun, SNR5 | ||||
| Buccaneer1, SNR10 | ||||
| Buccaneer1, SNR5 | ||||
| Destroyer engine, SNR10 | ||||
| Destroyer engine, SNR5 | ||||
| Factory1, SNR10 | ||||
| Factory1, SNR5 |
Testing on the unseen noise type: Pink at different SNRs below, and the clean speech (female, TIMIT) is the same.
Improved DNN |
LogMMSE |
Noisy |
|
| SNR20 | |||
| SNR15 | |||
| SNR10 | |||
| SNR5 | |||
| SNR0 | |||
| SNR-5 |
Testing on the unseen noise type: Exhibition at different SNRs below, and the clean speech (male, TIMIT) is the same.
Improved DNN |
LogMMSE |
Noisy |
|
| SNR20 | |||
| SNR15 | |||
| SNR10 | |||
| SNR5 | |||
| SNR0 | |||
| SNR-5 |
Section 2: Related waveforms refered in the submitted paper
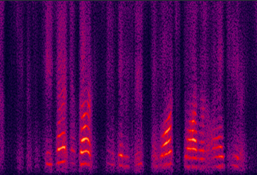

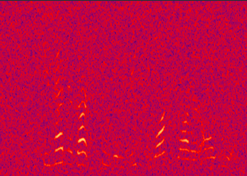
(a) DNN-baseline |
(b) clean |
(c) noisy |
Fig. 4 in the submitted paper to indicate the over-smoothing problem in the DNN-based method: Spectrograms of an utterance tested with AWGN at 0dB SNR: for the (a) DNN-baseline estimated (left), (b) the clean (middle) and (c) the noisy (right) speech.
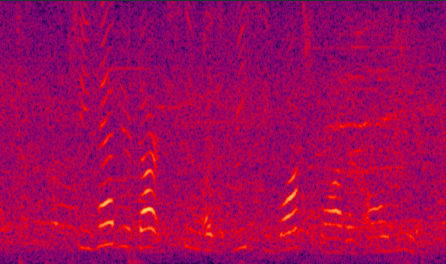
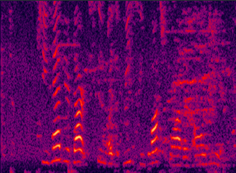

(a) noisy speech |
(b) LogMMSE |
(c) DNN baseline |
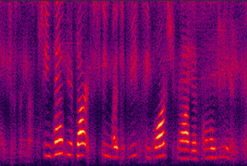
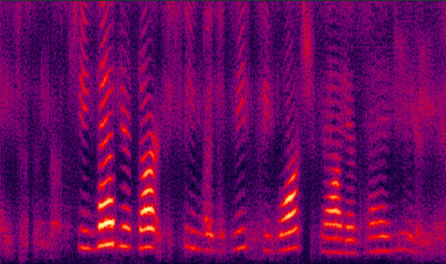
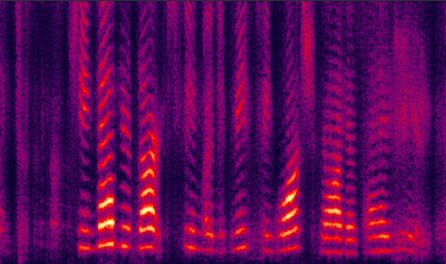

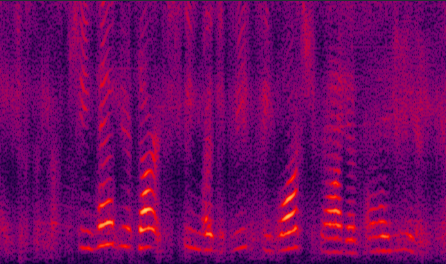
(e) improved by GV |
Fig. 8 in the submitted paper to compare the performance of different proposed systems and the traditional LogMMSE method: Spectrograms of an utterance tested with Exhibition (unseen) noise at SNR= 5dB. (a) noisy speech (PESQ=1.42), (b) LogMMSE (PESQ=1.83), (c) DNN baseline (PESQ=1.87), (d) improved by dropout (PESQ=2.06), (e) improved by GV equalization (PESQ=2.00), (f) improved by dropout and GV (PESQ=2.13), (g) jointly improved by dropout, NAT and GV equalization (PESQ=2.25), and the clean speech (PESQ=4.5).
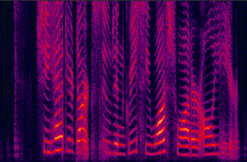
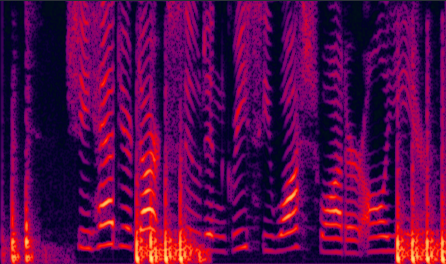
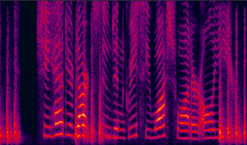
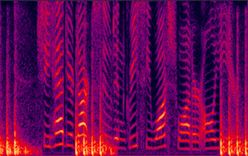
(b) LogMMSE enhanced |
(d) noisy speech |
Fig. 9 in the submitted paper to indicate the ability of suppression against non-stationary noise : Spectrograms of an utterance tested on Machine gun (unseen) noise at SNR= -5dB: with (a) 104-noise DNN enhanced (PESQ=2.78), (b) LogMMSE enhanced (PESQ=1.86), (c) 4-noise DNN enhanced (PESQ=2.14), and (c) noisy speech (PESQ=1.85).
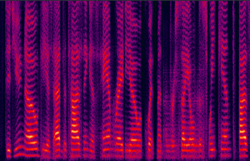
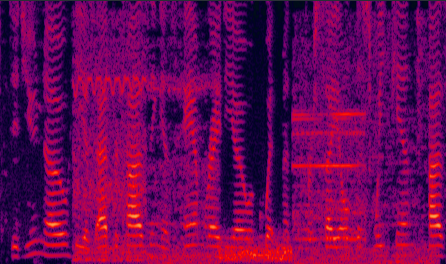
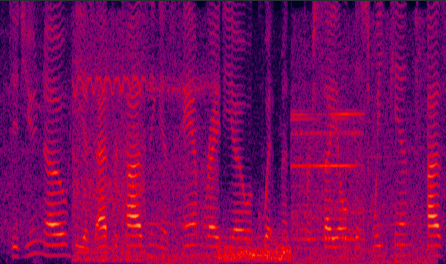
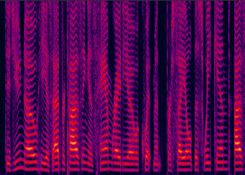
| (a) DNN enhanced |
(b) LogMMSE enhanced |
(c) noisy |
(d) clean |
Fig. 10 in the submitted paper to indicate the ability of suppression against severely changing noise envrionments (non-stationary) : Spectrograms of an utterance corrupted in succession by different noise types tested on changing noise environments at SNR = 5dB: (a) DNN enhanced (PESQ=2.99), (b) the LogMMSE enhanced (PESQ=1.46), (c) noisy (PESQ=2.05), and (d) clean speech (PESQ=4.50).
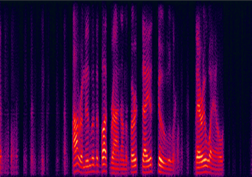
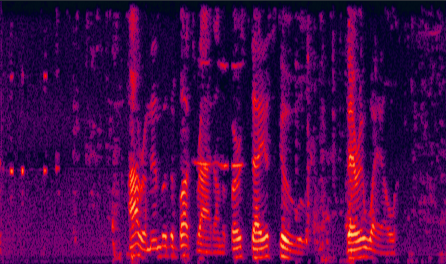

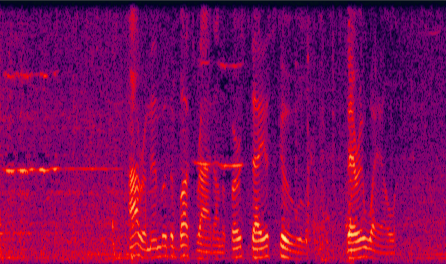
(a) improved DNN |
(b) LogMMSE |
(d) noisy |
Fig. 11 in the submitted paper to indicate the ability of enhancing the real-world noisy utterance : Spectrograms of a noisy utterance extracted from the movie Forrest Gump with: (a) improved DNN, (b) LogMMSE, (c) DNN model further post-processed using the LogMMSE method, and (d) noisy speech