|
Laplacian Pyramid Neural Network for Dense Continuous-Value Regression for Complex Scenes Xuejin Chen Xiaotian Chen Yiteng Zhang Xueyang Fu Zheng-Jun Zha* National Engineering Laboratory for Brain-inspired Intelligence Technology and Application University of Science and Technology of China IEEE Transactions on Neural Networks and Learning Systems 2020 |
|
Abstract: |
|
Many computer vision tasks, such as monocular depth estimation and height estimation from a satellite orthophoto, have a common underlying goal, which is regression of dense continuous values for the pixels given a single image. We define them as dense continuous-value regression (DCR) tasks. Recent approaches based on deep convolutional neural networks significantly improve the performance of DCR tasks, particularly on pixelwise regression accuracy. However, it still remains challenging to simultaneously preserve the global structure and fine object details in complex scenes. In this article, we take advantage of the efficiency of Laplacian pyramid on representing multiscale contents to reconstruct high-quality signals for complex scenes. We design a Laplacian pyramid neural network (LAPNet), which consists of a Laplacian pyramid decoder (LPD) for signal reconstruction and an adaptive dense feature fusion (ADFF) module to fuse features from the input image. More specifically, we build an LPD to effectively express both global and local scene structures. In our LPD, the upper and lower levels, respectively, represent scene layouts and shape details. We introduce a residual refinement module to progressively complement high-frequency details for signal prediction at each level. To recover the signals at each individual level in the pyramid, an ADFF module is proposed to adaptively fuse multiscale image features for accurate prediction. We conduct comprehensive experiments to evaluate a number of variants of our model on three important DCR tasks, i.e., monocular depth estimation, single-image height estimation, and density map estimation for crowd counting. Experiments demonstrate that our method achieves new state-of-the-art performance in both qualitative and quantitative evaluation on the NYU-D V2 and KITTI for monocular depth estimation, the challenging Urban Semantic 3D (US3D) for satellite height estimation, and four challenging benchmarks for crowd counting. These results demonstrate that the proposed LAPNet is a universal and effective architecture for DCR problems. |
|
Results: |
 |
|
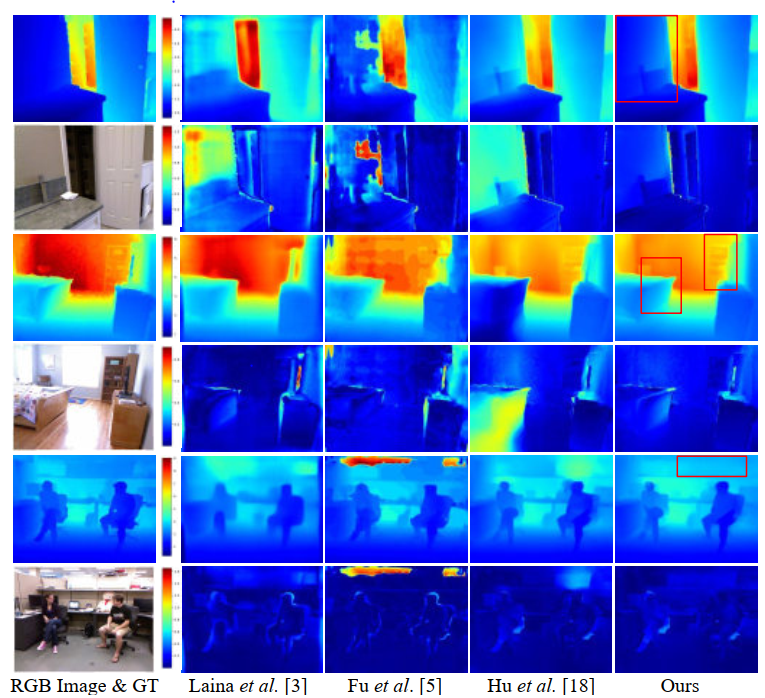
Qualitative results on the NYU-D V2 dataset. The predicted depth maps (top row) and the relative error maps (bottom row) are both shown. |
 |
| Qualitative comparison on the KITTI dataset. The predicted depth maps are shown on the top and the absolute error maps are shown on the bottom. |
 |
| Comparison of two types of ground truth and the errors between the predicted results of our method and Fu et al. compared with the annotated depth maps. Close-ups of two regions with occlusions are shown for each example. |
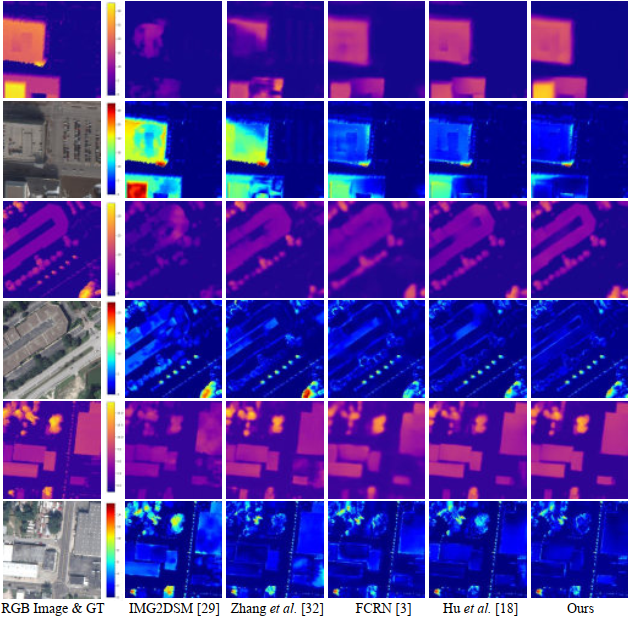 |
| Results of height estimation on the US3D dataset. The predicted height maps are shown on the top and the error maps are shown on bottom. |
 |
| Some crowd density maps generated by our method on ShanghaiTech Part A. From to to bottom: input images with crowd of various scales, the ground-truth density maps, and our estimated density maps. |
| Acknowledgements: |
|
This work was supported by the National Key Research & Development Plan of China under Grant 2017YFB1002202, the National Natural Science Foundation of China (NSFC) under Grants 61632006, U19B2038 and 61620106009, as well as the Fundamental Research Funds for the Central Universities under Grant WK3490000003. |
| Main References: |
|
[1] Junjie Hu, Mete Ozay, Yan Zhang, and Takayuki Okatani. Revisiting single image depth estimation: Toward higher resolution maps with accurate object boundaries. In IEEE Winter Conference on Applications of Computer Vision, 2019. [2] Huan Fu, Mingming Gong, Chaohui Wang, Kayhan Batmanghelich, and Dacheng Tao, Deep ordinal regression network for monocular depth estimation, in CVPR, 2018. |
| BibTex: |
| @article{Chen2020LAP-Net, author = {Chen, Xuejin and Chen, Xiaotian and Zhang, Yiteng and Fu, Xueyang and Zha, Zheng-Jun}, title = {Laplacian Pyramid Neural Network for Dense Continuous-Value Regression for Complex Scenes}, conference={IEEE Transactions on Neural Networks and Learning Systems}, year = {2020} } |
| Downloads: |
| Disclaimer: The paper listed on this page is copyright-protected. By clicking on the paper link below, you confirm that you or your institution have the right to access the corresponding pdf file. |
|
|
| Copyright ? 2018 GCL , USTC |