代码书写格式规范(未完待续)
为了使得代码格式更加的规范和方便阅读,对代码的格式也做一些要求:
这一章过于重要,以至于我一直都没有完成它,有太多的细节要思考和整理了
文件开头
最好使用Vivado生成文件,这样会在文件开头加上相应的注释信息,包括:模块名、项目名、日期、作者、功能解释、注释和版本等信息。下面是一个空白的例子(用Vivado新建工程会自动创建这个内容,同时填上相应的信息),不用Vivado的时候我的Vim也可以自动创建这段代码,看下面的动图演示:先输入title,然后按F12即可。
//////////////////////////////////////////////////////////////////////////////////
// Company:
// Engineer:
//
// Create Date:
// Design Name:
// Module Name:
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//////////////////////////////////////////////////////////////////////////////////

下面是我之前写的一个模块的文件头,作为示例。
//////////////////////////////////////////////////////////////////////////////////
// Company: USTC
// Engineer: Yu Wang
//
// Create Date: 2019/05/24 10:49:15
// Design Name: GBT Board1V0
// Module Name: elink_gearbox_4b_10b_comma_alignment
// Project Name:
// Target Devices: xc7k410tffg900-2L
// Tool Versions: Vivado 2018.1
// Description:
// One must be careful about the data sequence of the 10b
// dataout. The input of the DECODER module is from MSB to LSB, so that the
// output should be compatible with it. If the data is sent from LSB first,
// then everything is OK. IF NOT, a bit-reverse is needed. The bit order is
// set by LSB_OR_MSB.
// One must know that what you send to oserdes_4in1out module will appear on
// the output of elink_selectio_1in4out_dly_ctrl moudle. So that do not care
// about the data sequence in the serial transmission.
// One must also note that if MSB came first, the bit order is B9, B8,..., B0
// and the output 10b data is 9876543210; otherwise is B0, B1,..., B9.
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//////////////////////////////////////////////////////////////////////////////////
模块名
模块名必须和文件名一样!!!
模块名应当采用有意义的单词,并用小写字母+下划线”_”的方式将单词连接在一起
模块名应当采取 [对象]_[动作]的方式:如sram_ctrl.v, elink_selectio_1in4out_dly_ctrl.v
模块名后面的括号另起一行!!!,以便后面的端口对齐,如果有parameter也要另起一行,方便对齐,如下面代码所示
module usb_gbt_top #( parameter FEC_NUM = 16, parameter FEC_WIDTH = $clog2(FEC_NUM), parameter DEBUG_EN = 1, )( input CLK40M_PIN //... );top层的名字一定要鲜明,包含top字样
输入输出端口
采用Verilog-2001标准,也就是写成上面代码那样
每行只声明一个端口,有必要的时候在后面写上一定的注释
输入端口在最后加上_i
输出端口在后面加上_o
有必要时使用parameter,名字一定要大写
不要按输入输出的顺序排序,也不要按字母排序!!!
按照功能来排序,应当按照如下顺序:
- 时钟信号
- 复位信号
- 使能信号
- 控制信号
- 地址信号
- 数据
- 数据本身
- 数据valid
- 数据ready
当端口很多时,可以采用//----------的方式来区分每个功能分区的端口
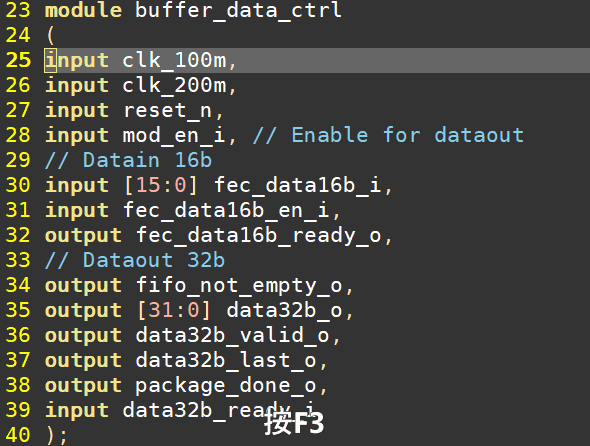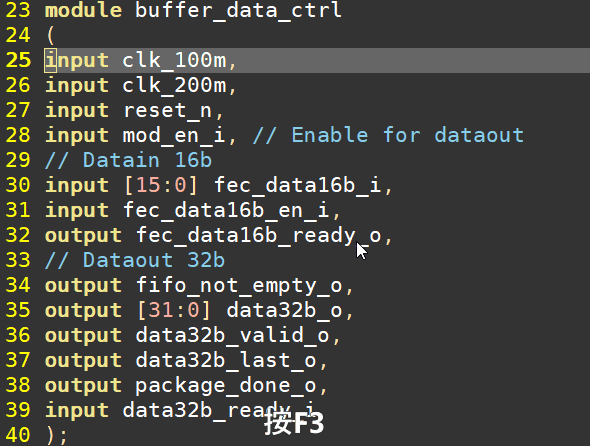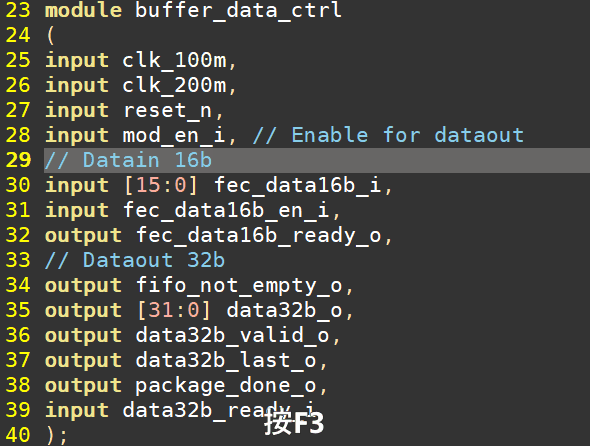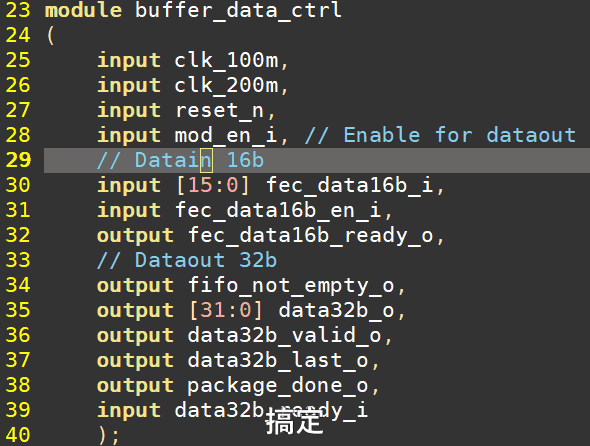
端口缩进!!!使用我的vim按F3会自动缩进,如下图所示
Tips:最后一个端口后面没有“,”
变量
变量命名要有意义,按照[所属目标]_[具体内容]_[r或者w]方式定义,如reg usb_data_valid_r; wire usb_data_ready_w;
reg型变量后面加上后缀_r,wire型变量后面加上后缀_w,如上面那条写的那样
数据位定义都是从高到低的:reg [7 : 0] uart_data_r; 不要reg
[0 : 7] uart_data_r;低电平的信号后面一定要带_n
用作时钟域同步的信号要加上_sync,如reg [1 : 0] trigger_sync_r;
[WIDTH - 1 : 0] 中的冒号和两边的值要加上空格隔开
任何运算符和变量之间都要用空格隔开
[a : 0] 和 [ 0 +: a] 等价,在使用for循环的时候很有用
如果有多个变量有相同的功能,直接定义成数组,不要每个变量都定义一个!!!
模块内的parameter一律定义为localparam,我比较喜欢的一个方式如下所示,可以对的很齐
localparam [1:0] IDLE = 2'd0, DATA_OUT = 2'd1, TLAST = 2'd2, DONE = 2'd3;即使是parameter的名字也要有意义,这样状态机才不会搞混
能用parameter解决的东西就不要用变量
- 普通变量的名字应当是:[对象]_[动作]_[后缀]的方式,比如说:data_credits_tx_w。采用这样的方式可以第一时间反应过来这个变量是属于哪个对象的。
- 状态机变量名应当是:[动作]_[对象],如:CLR_CREDIT,WAIT_DATA_DONE。采用这样的方式在读的时候可以很清楚这个状态是在做什么,符合语言的习惯
语句
每个语句都要独立成行,除非下面这种D触发器
always, for, while语句的begin在其下一行
initial, if, else语句的begin与其在同一行
end, endcase, endgenerate独占一行,绝对不要出现end else这样的情况
同一个逻辑块内不要空行,不同的逻辑块之间空一行,甚至注释空行,以显示他们之间的关系
每行尽量小于80个字符,增加代码可读性,尤其是喜欢用?:表达式的作者,换行的时候将运算符带着一起换行。如
RAM_din_r <= (baseline_calibration_on_in == 1'b1) ? current_calibration_data_w : ADC_data_in; always @ (posedge clk_25) // ADC threshold keep process begin if(!rstn) begin ADC_data_threshold_off_r <= 1'b1; end else if(ADC_data_threshold_valid_in == 1'b1 && ADC_data_threshold_ready_out == 1'b1 && ADC_data_threshold_chip_number_in == chip_number) begin ADC_data_threshold_off_r <= ADC_data_threshold_off_in; ADC_data_threshold_r[ADC_data_threshold_channel_number_in] <= ADC_data_threshold_in; end end用tab缩进代码,如果是用我的vim编辑代码直接按F3即可
每个文件不要太大,如果一个module包含了太多的代码,那么说明还有很多的改进空间
单比特信号不需要==1或者==0,如
if(usb_data_en_i == 1'b1) // 应当写作 if(usb_data_en_i) if(reset_n == 1'b0) // 应当写作 if(!reset_n)行尾不要加空格,如果用我的vim,按F3之后会自动把行尾多余的空格去掉
运算符和变量之间尽量加上空格
注释
- 代码尽量写得没有注释也能看懂,比如说usb_data32b_r, usb_data32b_valid_r, usb_data32b_ready_w, addr_wr_acq_w,这些信号自身就说明了其含义
- 端口加上注释解释,说明其用途,若一个模块有多个时钟域,还应当说明其时钟域
- 有一些特殊的设计和考虑,一定要加上注释
- 但是注释也不要乱加,如:// Data adder
- 很多作者都喜欢用/**/来注释掉老的代码块,这是一个好习惯,也是一个坏习惯
- 开始修改代码时,使用/**/注释,有助于调试和查看原有代码
- 新代码调试完成后,应当把/**/注释掉的老代码删除,没必要留在文件里
- 这些注释掉的代码可能永远都不会用了
- 如果带担心老代码有些有用的内容,可以看我的代码管理小节
代码功能举例
简单的D触发器
下面的代码可以实现一个带使能的异步复位D触发器,注意在时序逻辑代码里,寄存器不一定在不同分支里都要赋值,若不赋值,综合器会理解为保持上一次的值。但是在组合逻辑里不行,组合逻辑里寄存器在每个分支里都必须赋值,否则会生成latch
always @ (posedge clk_100m or negedge reset_n)
begin
if(!reset_n) begin
data32b_r <= 32'b0;
data32b_valid_r <= 1'b0;
end
else if(acq_data_ready_r) begin
data32b_r <= acq_data_r;
data_32b_valid_r <= 1'b1;
end
else begin
data_32b_valid_r <= 1'b0;
end
end
generate的例子
generate 普通代码
下面这段代码有些行已经超过了80个字符,是在没法换行了。
代码的目的是为了在一串10bits的数据流中找出是comma的那一段,也就是说实现一个1到10的串并转换之后,需要找到如何截断这10bit。
1转10最终的10bits数据会有10种可能性,因此需要选出其中对应为comma码的那一种,在下面的代码中,用for循环遍历一遍,找到comma的那一位
// K28.1, K28.5, K28.7 detect
// For easy reading the 10b coding data is arranged from LSB to MSB ie.
// abcdei fghj.
//--------------------------------------------------
// Code | 8bits data | RD- RD+ |
// | MSB-LSB | LSB-MSB |
//--------------------------------------------------
// k28.1 | 001_11100 | 001111_1001 110000_0110 |
//--------------------------------------------------
// k28.5 | 101_11100 | 001111_1010 110000_0101 |
//--------------------------------------------------
// k28.7 | 111_11100 | 001111_1000 110000_0111 |
//--------------------------------------------------
// In order to be compatible with the DECODER module the
// output data is from MSB to LSB
// The following parameter only given the common 7bits of comma, and is
// from MSB to LSB
localparam COMMA_N_REVISE = 7'b001_1111;
localparam COMMA_P_REVISE = ~COMMA_N_REVISE;
localparam COMMA_N = 7'b111_1100;
localparam COMMA_P = ~COMMA_N;
reg [19:0] rx_data_20b_r;
genvar bit_position_g;
wire [6:0] rx_data_comma_7bx10_w[0:9];
wire [9:0] comma_valid_bits_w;
generate begin
for (bit_position_g = 0; bit_position_g < 10; bit_position_g = bit_position_g + 1)
begin
assign rx_data10bx10_w[bit_position_g] = rx_data_20b_r[9+bit_position_g -: 10];
if (LSB_OR_MSB == 1) begin
assign rx_data_comma_7bx10_w[bit_position_g] = rx_data_20b_r[6+bit_position_g -: 7];
assign comma_valid_bits_w[bit_position_g] = ((rx_data_comma_7bx10_w[bit_position_g] == COMMA_P)
|| (rx_data_comma_7bx10_w[bit_position_g] == COMMA_N))
? 1'b1 : 1'b0;
end
else begin
assign rx_data_comma_7bx10_w[bit_position_g] = rx_data_20b_r[9+bit_position_g -: 7];
assign comma_valid_bits_w[bit_position_g] = ((rx_data_comma_7bx10_w[bit_position_g] == COMMA_P_REVISE)
|| (rx_data_comma_7bx10_w[bit_position_g] == COMMA_N_REVISE))
? 1'b1 : 1'b0;
end
end
end
endgenerate
generate 模块调用
当一个模块要被用好几次时,直接用generate生成很多这样的模块,用多位宽的寄存器进行输入,非常方便,如下面的代码,数据控制模块会对应多个前端,重复很多遍就好了
genvar ii;
for (ii = 0; ii < FEC_NUM; ii = ii + 1)
begin: fec_data_reconstruct
//instance:../fec_if/fec_data_ctrl.v
fec_data_ctrl#(
.DATA_THRESHOLD(DATA_THRESHOLD)
)fec_data_ctrl_mux(
.clk_100m(clk_100m),
.clk_200m(clk_200m),
.reset_n(reset_n),
.transmit_start_i(transmit_en_i),
// Datain 16b
.fec_data16b_i(fec_data16b_i[ii * 16 +: 16]),
.fec_data16b_en_i(fec_data16b_en_i[ii]),
// Dataout 32b
.fifo_empty_o(fec_fifo_empty_w[ii]),
.fifo_full_o(fec_fifo_full_w[ii]),
.data_over_th_o(fec_data_over_th_w[ii]),
.data32b_o(fec_data32b_int_w[ii * 32 +: 32]),
.data32b_valid_o(fec_data32b_valid_int_w[ii]),
.data32b_ready_i(data32b_ready_w[ii])
);
assign data32b_ready_w[ii] = (chn_select_r == ii)
? (fec_data32b_tready_i && fec_usr_data_en_r)
: 1'b0;
end
endgenerate
再如下面的代码,可以通过是否将parameter DEBUG_EN置1来选择是否要将变量加入ila
generate begin: data_mux_dbg
if(DEBUG_EN == 1) begin
(*mark_debug = "true"*) wire [31:0] fec_data32b_dbg_w;
assign fec_data32b_dbg_w = fec_data32b_o;
(*mark_debug = "true"*) wire fec_data32b_tvalid_dbg_w;
assign fec_data32b_tvalid_dbg_w = fec_data32b_tvalid_o;
(*mark_debug = "true"*) wire [2:0] c_state_dbg_w;
assign c_state_dbg_w = c_state;
(*mark_debug = "true"*) wire [FEC_NUM - 1 : 0] fec_fifo_empty_dbg;
assign fec_fifo_empty_dbg = fec_fifo_empty_w;
(*mark_debug = "true"*) wire [FEC_WIDTH - 1 : 0] chn_select_dbg;
assign chn_select_dbg = chn_select_r;
end
end
endgenerate
generate begin:debug_sipo_10b
if(DEBUG_EN == 1'b1)
begin
ila_rx_data_4b debug_rx_data_4b (
.clk(clk_40m), // input wire clk
.probe0(rx_data_4b_from_selectio_w) // input wire [0:0] probe0
);
(* mark_debug = "true" *) wire [9:0] rx_data_10b_from_gearbox_debug;
assign rx_data_10b_from_gearbox_debug = rx_data_10b_from_gearbox_w;
end
end
endgenerate
generate的活用
下面的代码是个优先编码器,是可综合的
module prio_encoder#
(
parameter LINES = 16, // The LINES must be pow(2, n). If not enough, add 0
parameter WIDTH = $clog2(LINES)
)(
input [LINES - 1 : 0] data_i,
output reg [WIDTH - 1 : 0] encoded_data_o
);
genvar gi;
reg flag;
integer i;
always@(*)
begin
encoded_data_o = 1'b1 << WIDTH;
flag = 1;
for(i = 0; flag && (i < LINES); i = i + 1 ) begin
if(data_i[i] == 1) begin
encoded_data_o = i;
flag = 0;
end
end
end
endmodule
其他
- always和@之间要有一个空格,@和自己的()之间没有空格
- 所有的运算符和操作数之间都要有空格